
一、方法区
Java 虚拟机有一个方法区域,该区域在所有 Java 虚拟机线程之间共享。方法区域类似于常规语言或操作系统进程中的“文本”段的编译代码的存储区域。它存储每个类的结构,如:运行时常量池、字段和方法数据,以及成员方法和构造方法的代码,包括用于类和实例初始化和接口初始化的特殊方法。
方法区域在虚拟机启动时创建。虽然方法区域在逻辑上是堆的一部分,但简单实现可以选择不对其进行垃圾收集或压缩。本规范不强制要求方法区域的位置或用于管理已编译代码的策略。所述方法区域可以是固定的大小,或者可以根据计算的要求扩大,如果不需要更大的方法区域,则可以缩小。方法区域的内存不需要是连续的。
Java 虚拟机实现可以为程序员或用户提供对方法区域初始大小的控制,以及在变大小方法区域的情况下对最大和最小方法区域大小的控制。如果方法区域中的内存不能用于满足分配请求,则 Java 虚拟机抛出OutOfMemoryError。
1、存储位置
JDK 8 以前方法区存放在堆里,叫做永久代。
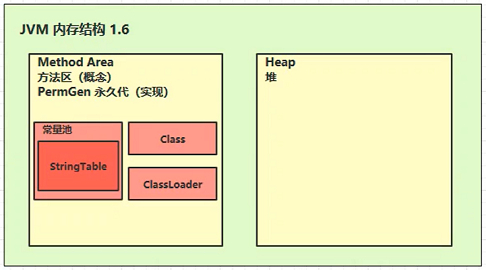
JDK 8 的方法区是直接使用操作系统的内存,叫元空间。
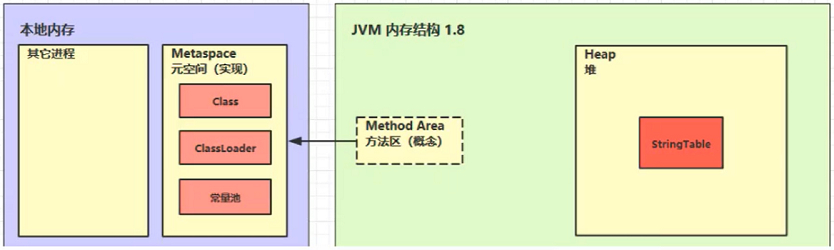
2、方法区内存溢出
(1)1.8 以前会导致永久代内存溢出
永久代内存溢出 java.lang.OutOfMemoryError: PermGen space。
-XX:MaxPermSize=8m
(2)1.8 之后会导致元空间内存溢出
关闭压缩类空间(Compressed class space),设置元空间的大小。
-XX:-UseCompressedClassPointers -XX:MaxMetaspaceSize=9m
演示元空间内存溢出 java.lang.OutOfMemoryError: Metaspace。
// 用来加载类的二进制字节码
public class Demo extends ClassLoader {
public static void main(String[] args) {
int j = 0;
try {
Demo test = new Demo();
for (int i = 0; i < 10000; i++, j++) {
// ClassWriter 作用是生成类的二进制字节码
ClassWriter cw = new ClassWriter(0);
// 版本号, public, 类名, 包名, 父类, 接口
cw.visit(Opcodes.V1_8, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null);
// 返回 byte[]
byte[] code = cw.toByteArray();
// 执行了类的加载
test.defineClass("Class" + i, code, 0, code.length); // Class 对象
}
} finally {
System.out.println(j);
}
}
}
3、运行时常量池
常量池就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息。运行时常量池,常量池是 *.class 文件中的,当该类被加载,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址。
(1)二进制字节码
运行以下代码。
public class Demo {
public static void main(String[] args) {
System.out.println("Hello World");
}
}
使用 javap -v Demo.class 反编译 class 文件,二进制字节码(类基本信息,常量池,类方法定义,虚拟机指令)。
Classfile /C:/software/IntelliJ IDEA Workspace/algorithm/out/production/algorithm/力扣/A/jvm/Demo.class
Last modified 2021-1-23; size 546 bytes
MD5 checksum 8ba4678874a0a6b3fc1649ef0025c7cb
Compiled from "Demo.java"
public class 力扣.A.jvm.Demo extends java.lang.ClassLoader
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #6.#20 // java/lang/ClassLoader."<init>":()V
#2 = Fieldref #21.#22 // java/lang/System.out:Ljava/io/PrintStream;
#3 = String #23 // Hello World
#4 = Methodref #24.#25 // java/io/PrintStream.println:(Ljava/lang/String;)V
#5 = Class #26 // 力扣/A/jvm/Demo
#6 = Class #27 // java/lang/ClassLoader
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 LocalVariableTable
#12 = Utf8 this
#13 = Utf8 L力扣/A/jvm/Demo;
#14 = Utf8 main
#15 = Utf8 ([Ljava/lang/String;)V
#16 = Utf8 args
#17 = Utf8 [Ljava/lang/String;
#18 = Utf8 SourceFile
#19 = Utf8 Demo.java
#20 = NameAndType #7:#8 // "<init>":()V
#21 = Class #28 // java/lang/System
#22 = NameAndType #29:#30 // out:Ljava/io/PrintStream;
#23 = Utf8 Hello World
#24 = Class #31 // java/io/PrintStream
#25 = NameAndType #32:#33 // println:(Ljava/lang/String;)V
#26 = Utf8 力扣/A/jvm/Demo
#27 = Utf8 java/lang/ClassLoader
#28 = Utf8 java/lang/System
#29 = Utf8 out
#30 = Utf8 Ljava/io/PrintStream;
#31 = Utf8 java/io/PrintStream
#32 = Utf8 println
#33 = Utf8 (Ljava/lang/String;)V
{
public 力扣.A.jvm.Demo();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/ClassLoader."<init>":()V
4: return
LineNumberTable:
line 8: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this L力扣/A/jvm/Demo;
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #3 // String Hello World
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
4、StringTable
在 JVM 里实现字符串池功能的是一个 StringTable,它的底层是一个HashTable,里面存的是字符串对象的引用(而不是字符串实例本身),真正的字符串实例是存放在堆内存中的(并且字符串池在逻辑上是属于运行时常量池的一部分)。
(1)特性
- 常量池中的字符串仅是符号,第一次用到时才变为对象。
- 利用串池的机制,来避免重复创建字符串对象。
- 字符串变量拼接的原理是 StringBuilder(1.8)。
- 字符串常量拼接的原理是编译期优化。
- 可以使用 intern 方法,主动将串池中还没有的字符串对象放入串池。
- 1.8 将这个字符串对象尝试放入串池,如果有则不会放入,如果没有则放入串池;最后返回的都是串池中的对象。
- 1.6 将这个字符串对象尝试放入串池,如果有则不会放入,如果没有则把此对象复制一份放入串池;最后返回的都是串池中的对象。
案例一
public class Demo {
public static void main(String[] args) {
String s1 = "a";
String s2 = "b";
String s3 = "ab";
}
}
上面代码的二进制字节码。
...
// 常量池
Constant pool:
#1 = Methodref #6.#24 // java/lang/Object."<init>":()V
#2 = String #25 // a
#3 = String #26 // b
#4 = String #27 // ab
#5 = Class #28 // 力扣/A/jvm/Demo
#6 = Class #29 // java/lang/Object
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 LocalVariableTable
#12 = Utf8 this
#13 = Utf8 L力扣/A/jvm/Demo;
#14 = Utf8 main
#15 = Utf8 ([Ljava/lang/String;)V
#16 = Utf8 args
#17 = Utf8 [Ljava/lang/String;
#18 = Utf8 s1
#19 = Utf8 Ljava/lang/String;
#20 = Utf8 s2
#21 = Utf8 s3
#22 = Utf8 SourceFile
#23 = Utf8 Demo.java
#24 = NameAndType #7:#8 // "<init>":()V
#25 = Utf8 a
#26 = Utf8 b
#27 = Utf8 ab
#28 = Utf8 力扣/A/jvm/Demo
#29 = Utf8 java/lang/Object
...
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=4, args_size=1
// 在 2 号常量池中加载一个信息,有可能是个常量(这里是常量),也有可能是个对象引用
0: ldc #2 // String a
// 将加载好的常量存入 1 号局部变量
2: astore_1
3: ldc #3 // String b
5: astore_2
6: ldc #4 // String ab
8: astore_3
9: return
LineNumberTable:
line 10: 0
line 11: 3
line 12: 6
line 13: 9
// 局部变量表
LocalVariableTable:
Start Length Slot Name Signature
0 10 0 args [Ljava/lang/String;
3 7 1 s1 Ljava/lang/String;
6 4 2 s2 Ljava/lang/String;
9 1 3 s3 Ljava/lang/String;
分析:常量池中的信息,都会被加载到运行时常量池中,最初 a、b、ab 都是常量池中的符号,还没有变为 java 字符串对象。ldc #2 会把 a 符号变成“a”字符串对象,ldc #3 会把 b 符号变成 “b”字符串对象。所有字符串对象都会加载到 StringTable 中,它是一个 HashTable 结构,值是唯一的,不能扩容。
案例二
public class Demo {
public static void main(String[] args) {
String s1 = "a";
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;
String s5 = "a" + "b";
}
}
上面代码的二进制字节码。
...Constant pool:
#1 = Methodref #10.#30 // java/lang/Object."<init>":()V
#2 = String #31 // a
#3 = String #32 // b
#4 = String #33 // ab
#5 = Class #34 // java/lang/StringBuilder
#6 = Methodref #5.#30 // java/lang/StringBuilder."<init>":()V
#7 = Methodref #5.#35 // java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
#8 = Methodref #5.#36 // java/lang/StringBuilder.toString:()Ljava/lang/String;
#9 = Class #37 // 力扣/A/jvm/Demo
#10 = Class #38 // java/lang/Object
#11 = Utf8 <init>
#12 = Utf8 ()V
#13 = Utf8 Code
#14 = Utf8 LineNumberTable
#15 = Utf8 LocalVariableTable
#16 = Utf8 this
#17 = Utf8 L力扣/A/jvm/Demo;
#18 = Utf8 main
#19 = Utf8 ([Ljava/lang/String;)V
#20 = Utf8 args
#21 = Utf8 [Ljava/lang/String;
#22 = Utf8 s1
#23 = Utf8 Ljava/lang/String;
#24 = Utf8 s2
#25 = Utf8 s3
#26 = Utf8 s4
#27 = Utf8 s5
#28 = Utf8 SourceFile
#29 = Utf8 Demo.java
#30 = NameAndType #11:#12 // "<init>":()V
#31 = Utf8 a
#32 = Utf8 b
#33 = Utf8 ab
#34 = Utf8 java/lang/StringBuilder
#35 = NameAndType #39:#40 // append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
#36 = NameAndType #41:#42 // toString:()Ljava/lang/String;
#37 = Utf8 力扣/A/jvm/Demo
#38 = Utf8 java/lang/Object
#39 = Utf8 append
#40 = Utf8 (Ljava/lang/String;)Ljava/lang/StringBuilder;
#41 = Utf8 toString
#42 = Utf8 ()Ljava/lang/String;
...
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=6, args_size=1
0: ldc #2 // String a
2: astore_1
3: ldc #3 // String b
5: astore_2
6: ldc #4 // String ab
8: astore_3
// java 代码中的第4行从这开始,创建一个StringBuilder对象
9: new #5 // class java/lang/StringBuilder
12: dup
// 调用无参构造方法
13: invokespecial #6 // Method java/lang/StringBuilder."<init>":()V
// 加载 s1 这个参数,局部变量 aload_1,即 a
16: aload_1
// 调用 append 方法
17: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
// 加载 s2 这个参数
20: aload_2
// 调用 append 方法
21: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
// 调用 toString 方法
24: invokevirtual #8 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
27: astore 4
// 在 4 号常量池中加载常量 ab
29: ldc #4 // String ab
31: astore 5
33: return
...
分析:String s4 = s1 + s2; 相当于 new StringBuilder().append("a").append("b").toString(),即 new String("ab"),它是一个新的对象,存放在堆中,没有存放在 StringTable 中。而 String s5 = "a" + "b"; 相当于 String s5 = "ab";,这是 javac 在编译期间的优化,结果已经在编译期确定为 ab。
System.out.println(s3 == s4); // false
System.out.println(s3 == s5); // true
案例三
演示字符串字面量是延迟成为对象的。
public class Demo {
public static void main(String[] args) {
int x = args.length;
System.out.println();
System.out.print("1");// 断点 1
System.out.print("2");
System.out.print("3");
System.out.print("4");
System.out.print("5");
System.out.print("6");
System.out.print("7");
System.out.print("8");
System.out.print("9");
System.out.print("0");
System.out.print("1");// 断点 2
System.out.print("2");
System.out.print("3");
System.out.print("4");
System.out.print("5");
System.out.print("6");
System.out.print("7");
System.out.print("8");
System.out.print("9");
System.out.print("0");
System.out.print(x);// 断点 3
}
}
使用 Idea 可以查看程序当前实例化对象的个数。观察 String 对象的个数。断点1 String 对象的个数 2117;断点2 String 对象的个数 2127;断点3 String 对象的个数 2127。

案例四
1.8 将这个字符串对象尝试放入串池,如果有则不会放入,如果没有则放入串池;最后返回的都是串池中的对象。
public class Demo {
// ["ab", "a", "b"]
public static void main(String[] args) {
String s = new String("a") + new String("b");
// 堆 new String("a") new String("b") new String("ab")
String s2 = s.intern(); // 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池, 会把串池中的对象返回
String x = "ab";
System.out.println(s2 == x); // true
System.out.println(s == x); // true
}
}
public class Demo {
// ["ab", "a", "b"]
public static void main(String[] args) {
String x = "ab";
String s = new String("a") + new String("b");
// 堆 new String("a") new String("b") new String("ab")
String s2 = s.intern(); // 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池, 会把串池中的对象返回
System.out.println(s2 == x); // true
System.out.println(s == x); // false
}
}
面试题
public class Demo {
public static void main(String[] args) {
String s1 = "a";
String s2 = "b";
String s3 = "a" + "b"; // ab
String s4 = s1 + s2; // new String("ab")
String s5 = "ab";
String s6 = s4.intern();
// 问
System.out.println(s3 == s4); // false
System.out.println(s3 == s5); // true
System.out.println(s3 == s6); // true
String x2 = new String("c") + new String("d"); // new String("cd")
x2.intern();
String x1 = "cd";
// 问,如果调换了【最后两行代码】的位置呢
System.out.println(x1 == x2);// true ,调换位置后是 false
}
}
(3)位置
在 1.8 的环境下执行会报 java.lang.OutOfMemoryError: Java heap space 堆空间溢出。
/**
* 演示 StringTable 位置
* 在jdk8下设置 -Xmx10m -XX:-UseGCOverheadLimit
* -Xms:初始堆大小,-Xmx:最大堆大小
* 在jdk6下设置 -XX:MaxPermSize=10m
*/
public class Demo {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
int i = 0;
try {
for (int j = 0; j < 260000; j++) {
list.add(String.valueOf(j).intern());
i++;
}
} catch (Throwable e) {
e.printStackTrace();
} finally {
System.out.println(i);
}
}
}
如果不加 -XX:-UseGCOverheadLimit 会报 java.lang.OutOfMemoryError: GC overhead limit exceeded 超出GC开销限制,报该错的原因,如果 98% 的时间发生在垃圾回收上,而只有 2% 的堆空间被回收了,这时候就会报错。
(4)垃圾回收
用以下参数执行以下代码:
-Xmx10m -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc
参数2的作用:打印字符串表的统计信息,可以查看常量池中字符串的个数和一些大小信息。
参数3的作用:打印垃圾回收的一些详细信息。
代码如下:
public class Demo {
public static void main(String[] args) throws InterruptedException {
int i = 0;
try {
} catch (Throwable e) {
e.printStackTrace();
} finally {
System.out.println(i);
}
}
}
控制台打印:
// 没有发生垃圾回收
0
Heap
...
// StringTable 的相关信息
StringTable statistics:
// 桶的个数
Number of buckets : 60013 = 480104 bytes, avg 8.000
// 存储字符串对象的个数
Number of entries : 1706 = 40944 bytes, avg 24.000
Number of literals : 1706 = 154296 bytes, avg 90.443
// 占用空间
Total footprint : = 675344 bytes
Average bucket size : 0.028
Variance of bucket size : 0.029
Std. dev. of bucket size: 0.169
Maximum bucket size : 2
上面是默认情况下,StringTable 的相关信息,接下来添加 100 个字符串。
public class Demo {
public static void main(String[] args) throws InterruptedException {
int i = 0;
try {
for (int j = 0; j < 100; j++) {
String.valueOf(j).intern();
i++;
}
} catch (Throwable e) {
e.printStackTrace();
} finally {
System.out.println(i);
}
}
}
控制台打印如下,可以观察到 Number of entries 的值增加了 100。
100
Heap
...
StringTable statistics:
Number of buckets : 60013 = 480104 bytes, avg 8.000
Number of entries : 1806 = 43344 bytes, avg 24.000
Number of literals : 1806 = 159096 bytes, avg 88.093
Total footprint : = 682544 bytes
Average bucket size : 0.030
Variance of bucket size : 0.030
Std. dev. of bucket size: 0.174
Maximum bucket size : 2
然后添加 10000 个字符串。
public class Demo {
public static void main(String[] args) throws InterruptedException {
int i = 0;
try {
for (int j = 0; j < 10000; j++) {
String.valueOf(j).intern();
i++;
}
} catch (Throwable e) {
e.printStackTrace();
} finally {
System.out.println(i);
}
}
}
控制台打印如下, Number of entries 的值并没有增加到 10000 多,因为发生了垃圾回收。
[GC (Allocation Failure) [PSYoungGen: 2048K->504K(2560K)] 2048K->624K(9728K), 0.0049977 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
10000
Heap
...
StringTable statistics:
Number of buckets : 60013 = 480104 bytes, avg 8.000
Number of entries : 1830 = 43920 bytes, avg 24.000
Number of literals : 1830 = 160880 bytes, avg 87.913
Total footprint : = 684904 bytes
Average bucket size : 0.030
Variance of bucket size : 0.031
Std. dev. of bucket size: 0.175
Maximum bucket size : 2
(5)性能调优
StringTable 底层是 Hashtable 来实现的,如果 hash 冲突过多会影响效率。使用以下参数来执行下面的代码:
-Xms:初始堆大小,-Xmx:最大堆大小,XX:StringTableSize:设置 StringTable 的大小。
-Xms500m -Xmx500m -XX:StringTableSize=200000 -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc
public class Demo {
public static void main(String[] args) throws IOException {
List<String> address = new ArrayList<>();
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) {
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if (line == null) {
break;
}
address.add(line.intern());
}
System.out.println("cost:" + (System.nanoTime() - start) / 1000000);
}
}
}
打印结果为:212,linux.words 文件中有 481501 个不同的字符串。用以下参数再次执行。
-Xms500m -Xmx500m -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc
jdk 默认的 StringTable 大小为 60013,打印结果为 cost:306。
总结
常量多的时,可以把桶调大一些,让 hash 分别均匀,减少 hash 冲突,可以提升性能。
二、直接内存
直接内存是指操作系统的内存,常见于 NIO 操作时,用于数据缓冲区;分配回收成本较高,但读写性能高;不受 JVM 内存回收管理。
java 原生 IO 读写文件的过程。
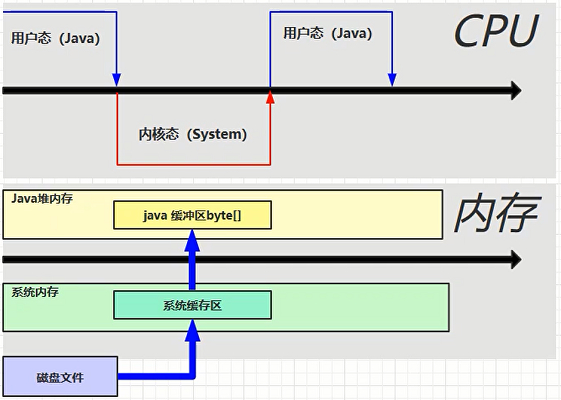
java NIO 读写文件的过程。NIO 的效率比 IO 高的原因就是使用了直接内存。直接内存是操作系统和 Java 代码都可以访问的一块区域,无需将代码从系统内存复制到 Java 堆内存,从而提高了效率。
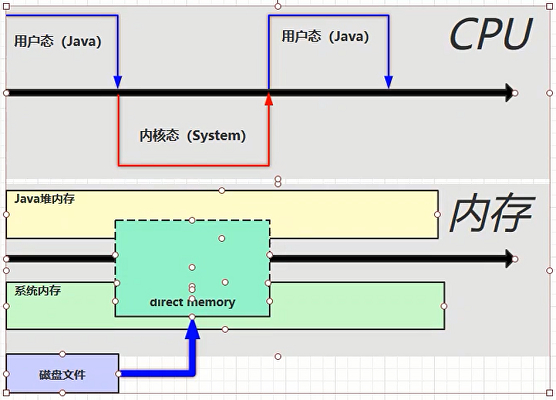
1、直接内存溢出
运行后报,java.lang.OutOfMemoryError: Direct buffer memory。
public class Demo {
static int _100MB = 1024 * 1024 *100;
public static void main(String[] args) throws IOException {
List<ByteBuffer> list = new ArrayList<>();
int i =0 ;
try {
while (true) {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_100MB);
list.add(byteBuffer);
i++;
}
}finally {
System.out.println(i);
}
}
}
2、分配和回收原理
直接内存分配的底层原理:Unsafe。使用 Unsafe 对象进行内存的分配后,回收需要主动调用 freeMemory 方法。使用 Unsafe 分配 1GB 直接内存,观察 Java 占用内存,因为分配的是直接内存,所以使用 Java 的内存诊断工具是诊断不到的。使用操作系统的任务管理器,观察编译器使用的内存。
public class Demo {
static int _1Gb = 1024 * 1024 * 1024;
public static void main(String[] args) throws IOException {
Unsafe unsafe = getUnsafe();
// 分配内存
long base = unsafe.allocateMemory(_1Gb);
unsafe.setMemory(base, _1Gb, (byte) 0);
System.in.read();
// 释放内存
unsafe.freeMemory(base);
System.in.read();
}
// JDK 不建议使用 Unsafe 直接操作内存,所以只能通过反射来获取对象
public static Unsafe getUnsafe() {
try {
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
Unsafe unsafe = (Unsafe) f.get(null);
return unsafe;
} catch (NoSuchFieldException | IllegalAccessException e) {
throw new RuntimeException(e);
}
}
}
使用 ByteBuffer 申请 1GB 的直接内存,ByteBuffer 底层就是使用 Unsafe 进行分配内存的。
public class Demo {
static int _1Gb = 1024 * 1024 * 1024;
public static void main(String[] args) throws IOException {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1Gb);
System.out.println("分配完毕...");
System.in.read();
System.out.println("开始释放...");
byteBuffer = null;
System.gc();
System.in.read();
}
}
通过观察内存的使用情况,发现执行 System.gc(); 直接内存被回收了。因为 ByteBuffer 的实现类内部,使用了 Cleaner(虚引用)来监测 ByteBuffer 对象,一旦 ByteBuffer 对象被垃圾回收,那么就会由 ReferenceHandler 线程通过 Cleaner 的 clean 方法调用 freeMemory 来释放直接内存。
直接内存的分配和释放是通过 Unsafe 来实现的,不是通过垃圾回收。直接内存的释放是借助 java 的虚以用的机制。有时候不让代码中显示调用 System.gc();,可以使用该参数 -XX:+DisableExplicitGC 禁用显示的垃圾回收。但又想快速回收直接内存,只能通过 Unsafe 进行操作。
标题:JVM 的方法区和直接内存
作者:Yi-Xing
地址:http://47.94.239.232/articles/2021/01/22/1611318487667.html
博客中若有不恰当的地方,请您一定要告诉我。前路崎岖,望我们可以互相帮助,并肩前行!