
一、类加载阶段
1、加载
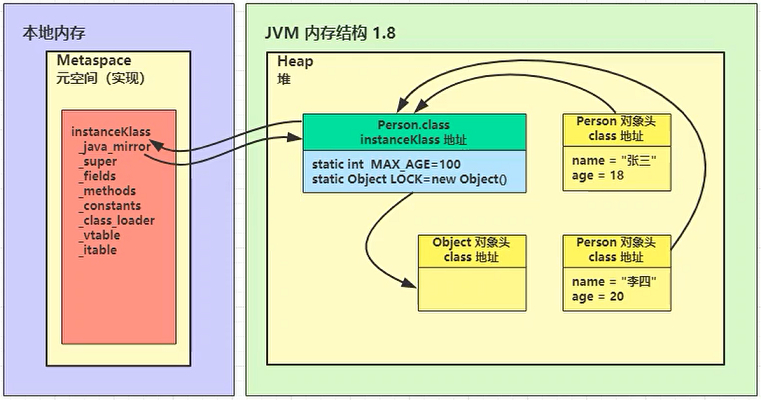
- 将类的字节码载入方法区(1.8后为元空间,在本地内存中)中,内部采用 C++ 的 instanceKlass 描述 java 类,它的重要 field 有:
- _java_mirror 即 java 的类镜像,例如对 String 来说,它的镜像类就是 String.class,作用是把 klass 暴露给 java 使用;
- _super 即父类;
- _fields 即成员变量;
- _methods 即方法;
- _constants 即常量池;
- _class_loader 即类加载器;
- _vtable 虚方法表;
- _itable 接口方法。
- 如果这个类还有父类没有加载,先加载父类;
- 加载和链接可能是交替运行的。
- instanceKlass 存储在方法区(1.8 后的元空间内),_java_mirror 是存储在堆中。
2、链接
验证:验证类是否符合 JVM规范,安全性检查。
准备:为 static 变量分配空间,设置默认值:
- static 变量在 JDK 7 以前是存储与 instanceKlass 末尾。但在 JDK 7 以后就存储在 _java_mirror 末尾了;
- static 变量分配空间和赋值是两个步骤。分配空间在准备阶段完成,赋值在初始化阶段完成;
- 如果 static 变量是 final 的基本类型,以及字符串常量,那么编译阶段值就确定了,赋值在准备阶段完成;
- 如果 static 变量是 final 的,但属于引用类型,那么赋值也会在初始化阶段完成。
解析:将常量池中的符号引用解析为直接引用。
- 未解析时,常量池中的看到的对象仅是符号,未真正的存在于内存中。
- 解析以后,会将常量池中的符号引用解析为直接引用,就知道其具体的内存地址了。
- 默认情况下类的加载是懒惰式的,如果只用到 C 没有用到 D,则 D 不会被加载。
- 使用 loadClass方法 加载 C,loadClass方法 只会对当前类进行加载,不会导致类的解析和初始化,所以 D 不会被加载。使用 HSDB 工具可以看到 D 没有被加载。
public class Demo8 {
public static void main(String[] args) throws IOException, ClassNotFoundException {
ClassLoader loader = Demo8.class.getClassLoader();
// loadClass 只加载不解析,不会导致类的解析和初始化
Class<?> c = loader.loadClass("B.A.jvm.C");
//用于阻塞主线程
System.in.read();
}
}
class C {
D d = new D();
}
class D {
}
3、初始化
初始化阶段就是执行类构造器 clinit() 方法的过程,虚拟机会保证这个类的构造方法的线程安全。
发生时机
类的初始化是懒惰的,以下情况会发生初始化:
- main 方法所在的类,总会被首先初始化;
- 首次访问这个类的静态变量或静态方法时;
- 子类初始化,如果父类还没初始化,会引发;
- 子类访问父类的静态变量,只会触发父类的初始化;
- Class.forName;
- new 会导致初始化。
以下情况不会发生初始化:
- 访问类的 static final 静态常量(基本类型和字符串)不会触发初始化;
- 类对象.class 不会触发初始化;
- 创建该类对象的数组不会触发初始化;
- 类加载器的 loadClass 方法;
- Class.forName 的参数 2 为 false 时。
public class Demo8 {
static {
System.out.println("main init");
}
public static void main(String[] args) throws ClassNotFoundException {
// 1. 静态常量(基本类型和字符串)不会触发初始化
System.out.println(B.b);
// 2. 类对象.class 不会触发初始化
System.out.println(B.class);
// 3. 创建该类的数组不会触发初始化
System.out.println(new B[0]);
// 4. 不会初始化类 B,但会加载 B、A
ClassLoader cl = Thread.currentThread().getContextClassLoader();
cl.loadClass("cn.itcast.jvm.t3.B");
// 5. 不会初始化类 B,但会加载 B、A
ClassLoader c2 = Thread.currentThread().getContextClassLoader();
Class.forName("cn.itcast.jvm.t3.B", false, c2);
// 1. 首次访问这个类的静态变量或静态方法时
System.out.println(A.a);
// 2. 子类初始化,如果父类还没初始化,会引发
System.out.println(B.c);
// 3. 子类访问父类静态变量,只触发父类初始化
System.out.println(B.a);
// 4. 会初始化类 B,并先初始化类 A
Class.forName("B.A.jvm.B");
}
}
class A {
static int a = 0;
static {
System.out.println("a init");
}
}
class B extends A {
final static double b = 5.0;
static boolean c = false;
static {
System.out.println("b init");
}
}
4、练习
从字节码分析,使用 a,b,c 这三个常量是否会导致 E 初始化。验证类是否被初始化,看改类的静态代码块是否被执行。
public class Demo8 {
public static void main(String[] args) {
System.out.println(E.a);
System.out.println(E.b);
// 触发类的初始化
System.out.println(E.c);
}
}
class E {
public static final int a = 10;
public static final String b = "hello";
// Integer.valueOf(20)
public static final Integer c = 20;
static {
System.out.println("init E");
}
}
懒惰初始化单例模式:
- 懒惰实例化;
- 初始化时的线程安全是有保障的。
public class Demo8 {
public static void main(String[] args) {
Demo9.test();
Demo9.getInstance();
}
}
class Demo9 {
private Demo9() {
}
static {
System.out.println("init Demo9");
}
// 不会导致内部类初始化
public static void test() {
System.out.println("test");
}
// 内部类中保存单例
private static class LazyHolder {
static final Demo9 INSTANCE = new Demo9();
static {
System.out.println("init LazyHolder");
}
}
// 第一次调用 getInstance 方法,才会导致内部类加载和初始化其静态成员
public static Demo9 getInstance() {
return LazyHolder.INSTANCE;
}
}
二、类加载器
| 名称 | 加载的类 | 说明 |
| - | - | - |
| Bootstrap ClassLoader(启动类加载器) | JAVA_HOME/jre/lib | 无法直接访问 |
| Extension ClassLoader(扩展类加载器) | JAVA_HOME/jre/lib/ext | 上级为Bootstrap,显示为null |
| Application ClassLoader(应用程序类加载器) | classpath | 上级为Extension |
| 自定义类加载器 | 自定义 | 上级为Application |
线程上下文类加载器是当前线程使用的类加载器,默认就是应用程序类加载器,它内部又是由 Class.forName 调用了线程上下文类加载器完成类加载,获取线程上下文类加载器的方法:
ClassLoader cl = Thread.currentThread().getContextClassLoader();
1、启动类加载器
可通过在控制台输入指令,使得类被启动类加器加载。用 Bootstrap 类加载器加载 load1 类:
public class F {
static {
System.out.println("bootstrap F init");
}
}
public class Load1 {
public static void main(String[] args) throws ClassNotFoundException {
// forName 对类进行加载链接初始化操作
Class<?> aClass = Class.forName("B.jvm.F");
// 获得该类的加载器
System.out.println(aClass.getClassLoader());
}
}
首先对程序进行编译,然后对 class 文件执行以下命令:
C:\software\IntelliJ IDEA Workspace\algorithm\out\production\algorithm>java -Xbootclasspath/a:. B.jvm.Load1
bootstrap F init
null
- null 表示该类被启动类加载器加载;
- -Xbootclasspath 表示设置 bootclasspath,启动类加载器的类路径;
- 其中 /a:. 表示将当前目录追加至 bootclasspath 之后;
- 可以用这个办法替换核心类:
- java -Xbootclasspath:
,用新路径替换旧路径; - java -Xbootclasspath/a:<追加路径>,后追加;
- java -Xbootclasspath/p:<追加路径>,前追加,用于替换 jvm 的核心类。
- java -Xbootclasspath:
2、扩展类加载器
如果 classpath 和 JAVA_HOME/jre/lib/ext 下有同名类,加载时会使用扩展类加载器加载。当应用程序类加载器发现扩展类加载器已将该同名类加载过了,则不会再次加载。
对上例中的 load1 类进行运行,结果为:
bootstrap F init
sun.misc.Launcher$AppClassLoader@18b4aac2
说明该类是被应用程序类加载器所加载。如果想让其被扩展类加载器加载。首先将 load1 类进行打包,因为扩展类加载的类必须是 jar 包。
jar -cvf my.jar B\jvm\F.class
然后将 jar 包放在 JAVA_HOME/jre/lib/ext 目录下,再运行。
bootstrap F init
sun.misc.Launcher$ExtClassLoader@7f31245a
3、双亲委派模式
所谓双亲委派模式,就是指调用类加载器 ClassLoader 的 loadClass 方法时,查找类的规则。下级加载类前,先判断上级是否已加载该类,如果都没加载,该加载器才进行加载。
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 首先查找该类是否已经被该类加载器加载过了
Class<?> c = findLoadedClass(name);
// 如果没有被加载过
if (c == null) {
long t0 = System.nanoTime();
try {
// 看是否被它的上级加载器加载过了 Extension 的上级是 Bootstarp,但它显示为null
if (parent != null) {
c = parent.loadClass(name, false);
} else {
// 看是否被启动类加载器加载过
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
// 捕获异常,但不做任何处理
}
if (c == null) {
// 如果还是没有找到,先让扩展类加载器调用findClass方法去找到该类,如果还是没找到,就抛出异常
// 然后让应用类加载器去找 classpath 下找该类
long t1 = System.nanoTime();
c = findClass(name);
// 记录时间
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
4、自定义类加载器
使用场景
- 想加载非 classpath 随意路径中的类文件;
- 通过接口来使用实现,希望解耦时,常用在框架设计;
- 这些类希望予以隔离,不同应用的同名类都可以加载,不冲突,常见于 tomcat 容器。
步骤
- 继承 ClassLoader 父类;
- 要遵从双亲委派机制,重写 findClass 方法;
- 不是重写 loadClass 方法,否则不会走双亲委派机制。
- 读取类文件的字节码;
- 调用父类的 defineClass 方法来加载类;
- 使用者调用该类加载器的 loadClass 方法。
确认唯一类,要包名、类名相同,同时类加载器也得相同。
public class Load1 {
public static void main(String[] args) throws Exception {
MyClassLoader classLoader = new MyClassLoader();
Class<?> c1 = classLoader.loadClass("A");
Class<?> c2 = classLoader.loadClass("A");
// 类文件只会加载一次,第一次加载放在自定义类加载器缓存中,第二次加载时发现缓存中已经有了
System.out.println(c1 == c2); // true
// 如果使用不同的类加载器;确认唯一类,要包名、类名相同,同时类加载器也得相同,它会加载两次
MyClassLoader classLoader2 = new MyClassLoader();
Class<?> c3 = classLoader2.loadClass("A");
System.out.println(c1 == c3); // false
c1.newInstance();
}
}
class MyClassLoader extends ClassLoader {
@Override
// name 就是类名称
protected Class<?> findClass(String name) throws ClassNotFoundException {
// 定义加载类的 class 文件路径
String path = "D:\\" + name + ".class";
try {
ByteArrayOutputStream os = new ByteArrayOutputStream();
Files.copy(Paths.get(path), os);
// 得到字节数组
byte[] bytes = os.toByteArray();
// byte[] -> *.class
return defineClass(name, bytes, 0, bytes.length);
} catch (IOException e) {
e.printStackTrace();
throw new ClassNotFoundException("类文件未找到", e);
}
}
}
三、运行期优化
Java程序最初是通过解释器(Interpreter)进行解释执行的,当虚拟机发现某个方法或代码块的运行特别频繁时,就会把这些代码认定为“热点代码”(Hot Spot Code)。为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各种层次的优化,完成这个任务的编译器称为即时编译器(Just In Time Compiler,简称JIT编译器)。
解释器与编译器两者各有优势:当程序需要迅速启动和执行的时候,解释器可以首先发挥作用,省去编译的时间,立即执行。在程序运行后,随着时间的推移,编译器逐渐发挥作用,把越来越多的代码编译成本地代码之后,可以获取更高的执行效率。当程序运行环境中内存资源限制较大(如部分嵌入式系统中),可以使用解释执行节约内存,反之可以使用编译执行来提升效率。
1、逃逸分析
public class F1 {
public static void main(String[] args) {
for (int i = 0; i < 200; i++) {
long start = System.nanoTime();
for (int j = 0; j < 1000; j++) {
// 循环创建对象
new Object();
}
long end = System.nanoTime();
System.out.printf("%d\t%d\n", i, (end - start));
}
}
}
观察运行结果可以看到,同样的代码后续的执行时间越来越短。由于即时编译器编译本地代码需要占用程序运行时间,要编译出优化程度更高的代码,所花费的时间可能更长;而且想要编译出优化程度更高的代码,解释器可能还要替编译器收集性能监控信息,这对解释执行的速度也有影响。为了在程序启动响应速度与运行效率之间达到最佳平衡,HotSpot虚拟机还会逐渐启用分层编译(Tiered Compilation)的策略。
JVM 将执行状态分成了 5 个层次:
- 0层,解释执行(Interpreter),将字节码解释为机器码;
- 1层,使用 C1 即时编译器编译执行(不带 profiling);
- 2层,使用 C1 即时编译器编译执行(带基本的 profiling);
- 3层,使用 C1 即时编译器编译执行(带完全的 profiling);
- 4层,使用 C2 即时编译器编译执行。
profiling 是指在运行过程中收集一些程序执行状态的数据,即信息统计工作,例如:方法的调用次数、循环的回边次数等。
即时编译器(JIT)与解释器的区别:
- 解释器是将字节码解释为机器码,下次即使遇到相同的字节码,仍会执行重复的解释;
- JIT 是将一些字节码编译为机器码,并存入 Code Cache,下次遇到相同的代码,下次遇到相同的代码,直接执行,无需再编译;
- 解释器是将字节码解释为针对所有平台都通用的机器码;
- JIT 会根据平台类型,生成平台特定的机器码。
对于占据大部分的不常用的代码,我们无需耗费时间将其编译成机器码,而是采取解释执行的方式运行;另一方面,对于仅占据小部分的热点代码,我们则可以将其编译成机器码,以达到理想的运行速度。执行效率上简单比较一下 :Interpreter < C1(可以提升5倍左右) < C2(可以提升10~100倍),总的目标是发现热点代码 (hotspot名称的由来)优化之。
刚才的一种优化手段称之为逃逸分析,发现新建的对象是否逃逸。可以使用 -XX:-DoEscapeAnalysis 关闭,默认打开,再运行刚才的示例观察结果。会才发现后续的运行时间没有大缩短了。
2、方法内联
private static int square(final int i) {
return i * i;
}
System.out.println(square(9));
如果发现 square 是热点方法,并且长度不太长时,会进行内联,所谓的内联就是把方法内代码拷贝、粘贴到调用者的位置。
System.out.println(9 * 9);
还能够进行常量折叠(constant folding)的优化。
System.out.println(81);
运行以下代码,观察其运行结果:
public class F1 {
public static void main(String[] args) {
int x = 0;
for (int i = 0; i < 500; i++) {
long start = System.nanoTime();
for (int j = 0; j < 1000; j++) {
x = square(9);
}
long end = System.nanoTime();
System.out.printf("%d\t%d\t%d\n", i, x, (end - start));
}
}
private static int square(final int i) {
return i * i;
}
}
- -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining:打印 inlining 信息;
- -XX:CompileCommand=dontinline,*F1.square:禁止某个方法 inlining,运行后发现不会出现结果为 0 的时间。
3、字段优化
public class F1 {
int[] elements = randomInts(1_000);
static int sum = 0;
private static int[] randomInts(int size) {
ThreadLocalRandom random = ThreadLocalRandom.current();
int[] values = new int[size];
for (int i = 0; i < size; i++) {
values[i] = random.nextInt();
}
return values;
}
public void test1() {
for (int i = 0; i < elements.length; i++) {
doSum(elements[i]);
}
}
public void test2() {
int[] local = this.elements;
for (int i = 0; i < local.length; i++) {
doSum(local[i]);
}
}
public void test3() {
for (int element : elements) {
doSum(element);
}
}
static void doSum(int x) {
sum += x;
}
}
在上述的示例中,doSum() 方法是否内联会影响 elements 成员变量读取的优化。如果 doSum() 方法内联了,test1 方法会被优化成下面的样子(伪代码)。
public void test1() {
// elements.length 首次读取会缓存起来 -> int[] local,机器码做的处理
// 后续 999 次 求长度 <- local
for (int i = 0; i < elements.length; i++) {
// 1000 次取下标 i 的元素 <- local
sum += elements[i];
}
}
可以节省 1999 次 Field 字段读取操作,但如果 doSum() 方法没有内联,则不会进行上面的优化。
本地变量访问长度、数据时,不需要去 class 元数据那里找,在本地变量就可以找到了,相当于手动优化。但是方法内联是由虚拟机来优化的。所以,test3 方法与 test2 方法是等价的,test1 方法是运行期间优化了,test2 方法是手动优化了, test3 方法的 foreach 是编译期间优化了。
标题:JVM 类加载
作者:Yi-Xing
地址:http://47.94.239.232/articles/2021/02/09/1612850484384.html
博客中若有不恰当的地方,请您一定要告诉我。前路崎岖,望我们可以互相帮助,并肩前行!